Abstract
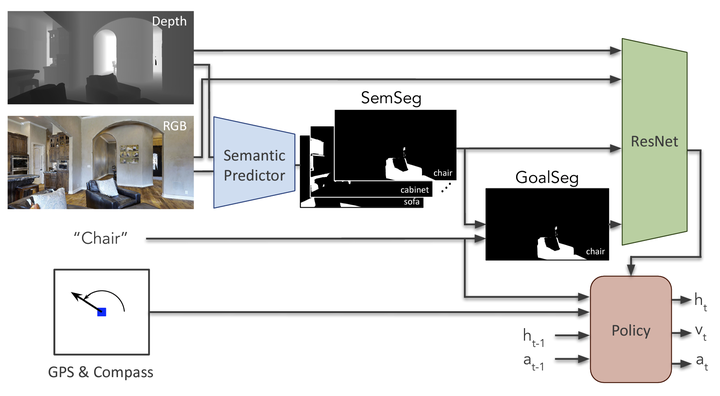
Can general-purpose neural models learn to navigate? For PointGoal navigation, the answer is a clear yes mapless neural models composed of task-agnostic components (CNNs and RNNs) trained with large-scale model-free reinforcement learning achieve near-perfect performance. However, for ObjectGoal navigation, this is an open question; one we tackle in this paper. The current best-known result on ObjectNav with general-purpose models is 6% success rate. First, we show that the key problem is overfitting. Large-scale training results in 94% success rate on training environments and only 8% in validation.
Type
Publication
In International Conference on Computer Vision (ICCV)