Waypoint Models for Instruction-guided Navigation in Continuous Environments
Abstract
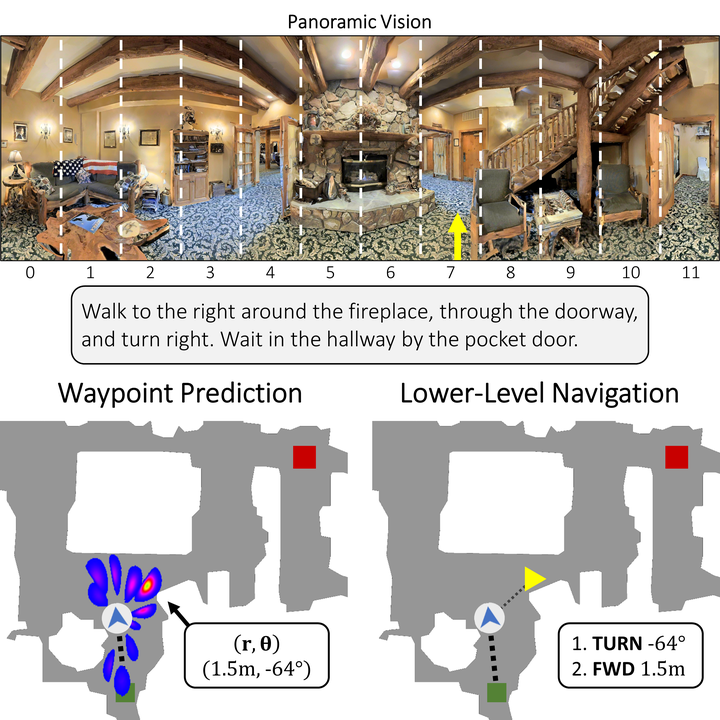
Little inquiry has explicitly addressed the role of action spaces in language-guided visual navigation – either in terms of its effect on navigation success or the efficiency with which a robotic agent could execute the resulting trajectory. Building on the recently released VLN-CE setting for instruction following in continuous environments, we develop a class of language-conditioned waypoint prediction networks to examine this question. We vary the expressivity of these models to explore a spectrum between low-level actions and continuous waypoint prediction. We measure task performance and estimated execution time on a profiled LoCoBot robot. We find more expressive models result in simpler, faster to execute trajectories, but lower-level actions can achieve better navigation metrics by better approximating shortest paths. Further, our models outperform prior work in VLN-CE and set a new state-of-the-art on the public leaderboard – increasing success rate by 4% with our best model on this challenging task.